In addition to our signature text analysis,, Sturdy Statistics also performs text classification. Our proprietary classification algorithms excel precisely where most other classification models struggle: classifying long documents, with multiple categories, and few labeled examples. While these important aspects aren’t often emphasized in machine learning research, in our experience they are fundamental to the practical application of machine learning.
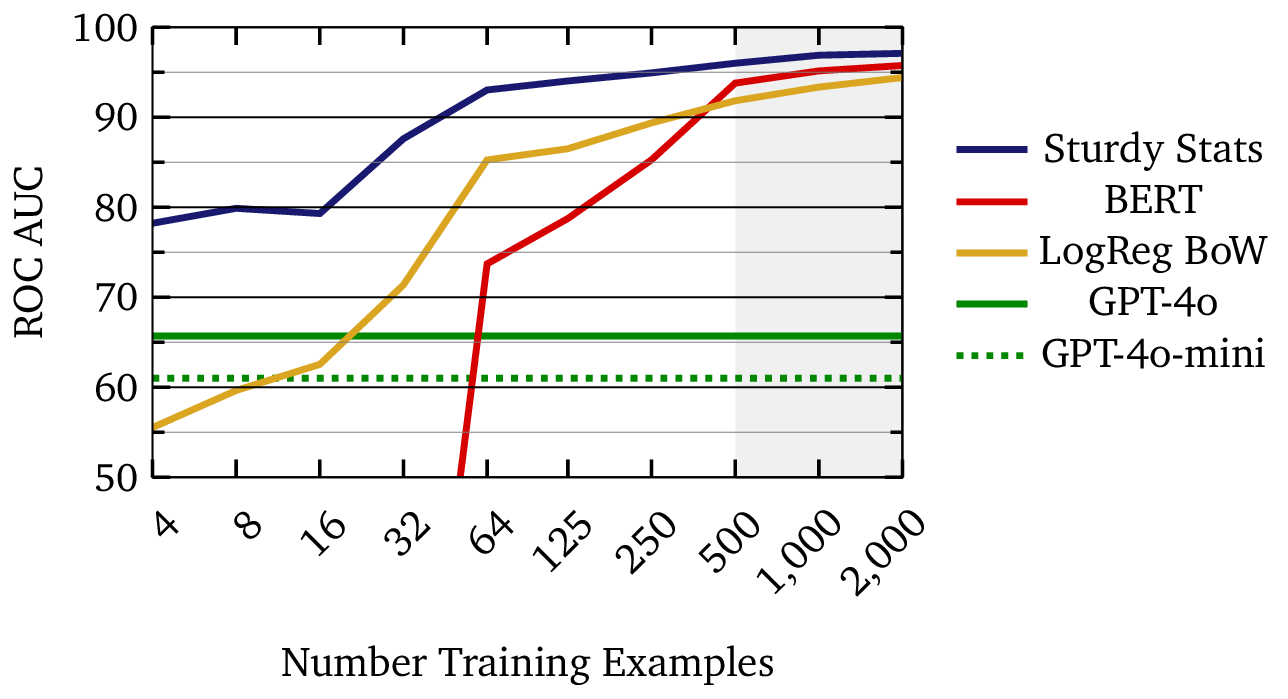
The figure below compares learning curves for three different document classification technologies. The learning curve for a machine learning model demonstrates how the model’s performance improves as it trains on more data; in effect, it shows how well the machine learning model actually “learns.” In this example, the Sturdy Statistics model reaches a score of 90% with just a few dozen examples; a single person could curate such a dataset in under an hour. On the other hand, the BERT and logistic regression models require roughly ten times as much data (∼500 examples) to reach the same performance. Large, purpose-built datasets are time-consuming and expensive to curate; in our experience, data availability is the limiting factor for most industrial machine learning applications. Using an AI technology which can operate with 1/10th as much data provides a tremendous competitive advantage.
One of the most distinctive features of our classification models is their fundamental explainability: users of Sturdy Statistics models are able to understand precisely how a model arrives at each specific prediction. This is extremely unusual in text classification, except for the simplest models such as logistic regression; typically, AI “explainability” involves significant post-processing and interpretation of the prediction, very often using another (and usually opaque) AI model to aid in the analysis. The extreme transparency of Sturdy Statistics models builds trust with users, and might even be required in sensitive applications like legal, medical, or financial decision-making, where incorrect or biased classifications have significant consequences.
The example below shows the explanation of a correct prediction from our model. The input document was a patent description, and the classification task is to predict the category (known as the CPC code) for the patent. In this case, our model correctly predicted that the patent belongs in the “construction” category. We can inspect which sentences, and which words within those sentences, most contributed to the prediction.
The figure shows that 4 out of 159 sentences in the description contributed substantially the prediction; interestingly, most of these are contiguous, and center on the “SUMMARY OF THE INVENTION” section heading. Thus, we can see that the model has indeed surfaced the “right” portions of the document for the task. (At least, the same portions I would have looked at if given this task!) We can also see that the words wellbore, casing, drilling, bonding, and adhesion contributed appreciably to the prediction, whereas words like pressure and temperature do not. This makes sense in light of the fact that other patent categories, such as “Physics” or “Engineering” might also uses these terms. The words wellbore and cement are more specific to construction. These results show that the model has not only made a correct prediction, but that it has done so for appropriate and understandable reasons.
The text classification API offers yet another means to automatically structure documents: first, by categorizing them, and next, by ranking the portions most relevant to each category. The structure imputed by our classification API works in tandem with the structure inferred by our text analysis API.
For more information, see our detailed description of our text classification feature.